
Page 164 - 2025年7月防腐蚀专辑
P. 164
王亚鑫等:人工智能技术在防腐涂料研发中的应用研究
防腐涂料中面漆配方数据量对基于 RM 训练模型预
测效果的影响;其中特征提取仅考虑原材料的种类
和用量,标签为耐老化性,测试集比例为 0. 2,探讨配
方数据量如何影响模型的准确性和有效性,结果如
R 2
表 1 所示。在评估结果中以 MSE、RMSE 及 MAE 衡量
模型预测值与实际值之间的差异,数值越小差异越
小。R 用来衡量模型解释数据方差的能力,值域为
2
0~1,数值越接近 1表示模型拟合效果越好。
表1 不同数据量下误差分析 典型特征数量/个
Table 1 Error analysis under different data volumes ? ? ?
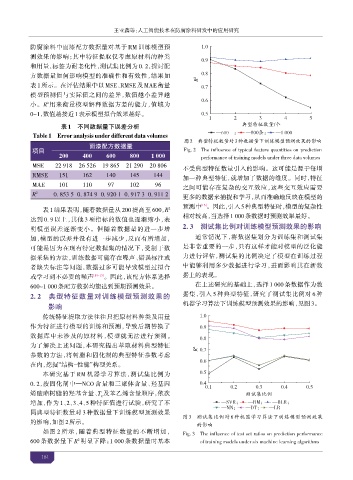
图2 典型特征数量对3种数据量下训练模型预测效果的影响
面漆配方数据量
项目 Fig. 2 The influence of typical feature quantities on prediction
200 400 600 800 1 000 performance of training models under three data volumes
MSE 22 918 26 526 19 865 21 290 20 806
不受典型特征数量引入的影响。这可能是源于每增
RMSE 151 162 140 145 144 加一种典型特征,就增加了数据的维度。同时,特征
MAE 101 110 97 102 96 之间可能存在复杂的交互效应,这些交互效应需要
R 2 0. 853 5 0. 874 9 0. 920 1 0. 917 3 0. 911 2 更多的数据来捕捉和学习,从而准确地反映在模型的
[16]
表 1 结果表明,随着数据量从 200 提高至 600,R 2 预测中 。因此,引入5种典型特征时,模型的复杂性
相对较高,当选择 1 000条数据时预测效果最好。
达到 0. 9 以上,其他 3 项指标的数值也逐渐缩小,表
明模型误差逐渐变小。但随着数据量的进一步增 2. 3 测试集比例对训练模型预测效果的影响
加,模型的误差并没有进一步减少,反而有所增加, 通常情况下,将数据集划分为训练集和测试集
可能是因为在现有特定数据集的情况下,受制于数 是非常重要的一步,只有这样才能对模型的泛化能
据采集的方法,训练数据可能存在噪声、错误标注或 力进行评估,测试集的比例决定了模型在训练过程
者缺失标注等问题,数据过多可能导致模型过拟合 中能够利用多少数据进行学习,进而影响其在新数
或学习到不必要的噪声 [14-15] 。因此,该配方体系选择 据上的表现。
600~1 000条配方数据均能达到预期预测效果。 在上述研究的基础上,选择 1 000 条数据作为数
2. 2 典型特征数量对训练模型预测效果的 据集,引入 5 种典型特征,研究了测试集比例对 6 种
影响 机器学习算法下训练模型预测效果的影响,见图 3。
传统特征提取方法往往只把原材料种类及用量
作为特征进行模型的训练和预测,导致后期替换了
数据库中未涉及的原材料,模型就无法进行预测。
为了解决上述问题,本研究提出萃取材料典型特征
R 2
参数的方法,将树脂和固化剂的典型特征参数考虑
在内,挖掘“结构-性能”构型关系。
本研究基于 RM 机器学习算法,测试集比例为
0. 2,按固化剂中—NCO 含量和三聚体含量、羟基丙
及苯乙烯含量顺序,依次
测试集比例
烯酸酯树脂的羟基含量、T g
增加,作为 1、2、3、4、5 种特征值进行试验,研究了不 ?473 ?3. ?#-3
?// ?%5 ?-3
同典型特征数量对 3 种数据量下训练模型预测效果
图3 测试集比例对 6 种机器学习算法下训练模型预测效果
的影响,如图2所示。
的影响
如图 2 所示,随着典型特征数量的不断增加,
Fig. 3 The influence of test set ratios on prediction performance
600 条数据量下 R 明显下降;1 000 条数据量时基本 of training models under six machine learning algorithms
2
161